Building a fast modern dark web crawler
I have been passionated by web crawler for a long time. I have written several one in many languages such as C++, JavaScript (Node.JS), Python, … and I love the theory behind them.
But first of all, what is a web crawler?
What is a web crawler?⌗
A web crawler is a computer program that browse the internet to index existing pages, images, PDF, … and allow user to search them using a search engine. It’s basically the technology behind the famous google search engine.
Typically a efficient web crawler is designed to be distributed: instead of a single program that runs on a dedicated server, it’s multiples instances of several programs that run on several servers (eg: on the cloud) that allows better task repartition, increased performances and increased bandwidth.
But distributed softwares does not come without drawbacks: there is factors that may add extra latency to your program and may decrease performances such as network latency, synchronization problems, poorly designed communication protocol, etc…
To be efficient, a distributed web crawler has to be well designed: it is important to eliminate as many bottlenecks as possible: as french admiral Olivier Lajous has said:
The weakest link determines the strength of the whole chain.
Trandoshan: a dark web crawler⌗
You may know that there is several successful web crawler running on the web such as google bot. So I didn’t wanted to make a new one again. What I wanted to do this time was to build a web crawler for the dark web.
What’s the dark web?⌗
I won’t be too technical to describe what the dark web is, since it may need is own article.
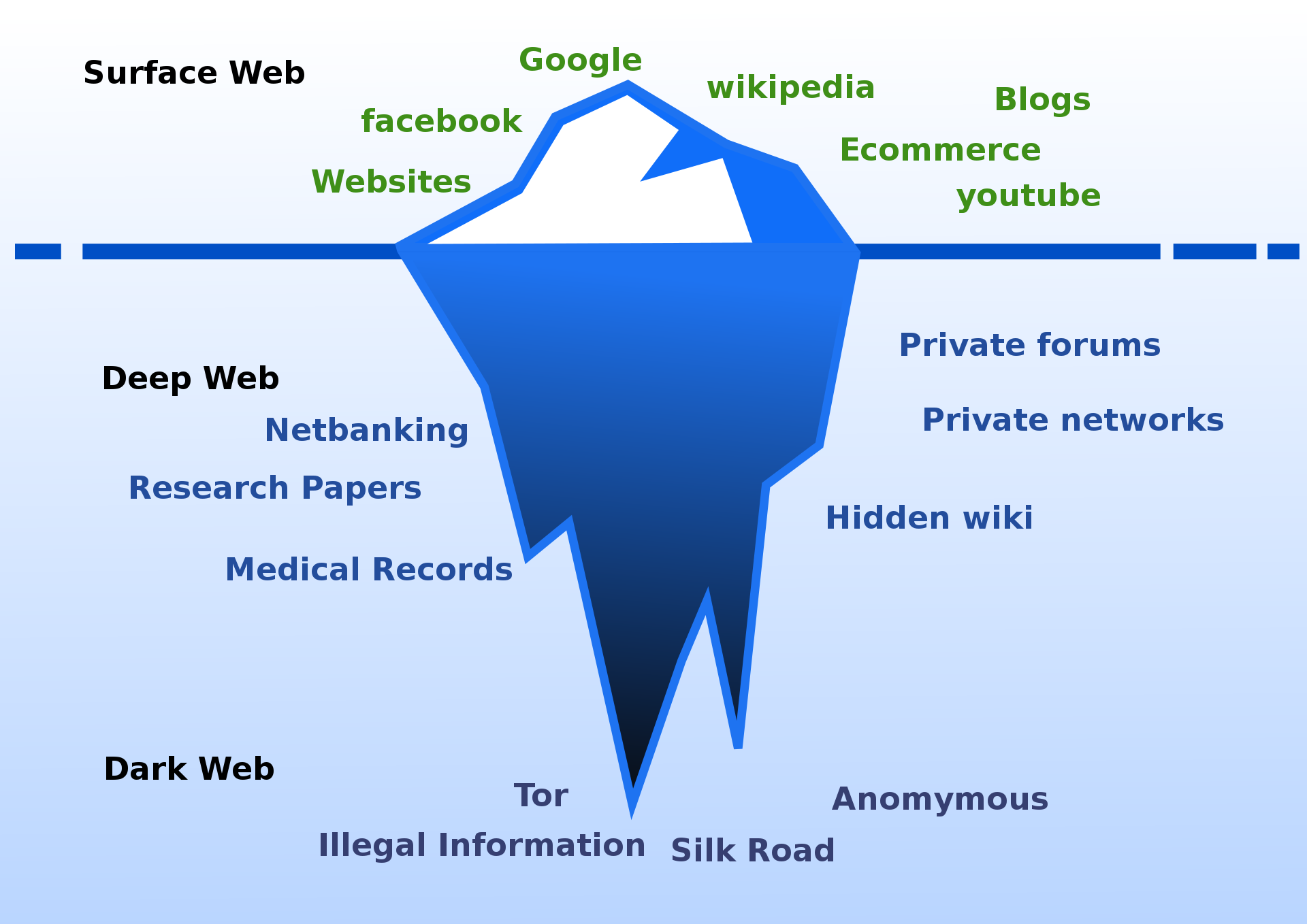
The web is composed of 3 layers and we can think of it like an iceberg:
- The Surface Web, or Clear Web is the part that we browse everyday. It’s indexed by popular web crawler such as Google, Qwant, Duckduckgo, etc…
- The Deep Web is a part of the web non indexed, It means that you cannot find these websites using a search engine but you’ll need to access them by knowing the associated URL / IP address.
- The Dark Web is a part of the web that you cannot access using a regular browser. You’ll need to use a particular application or a special proxy. The most famous part of the dark web are the hidden services built on the tor network. They can be accessed using special URL who ends with .onion
How is Trandoshan designed?⌗
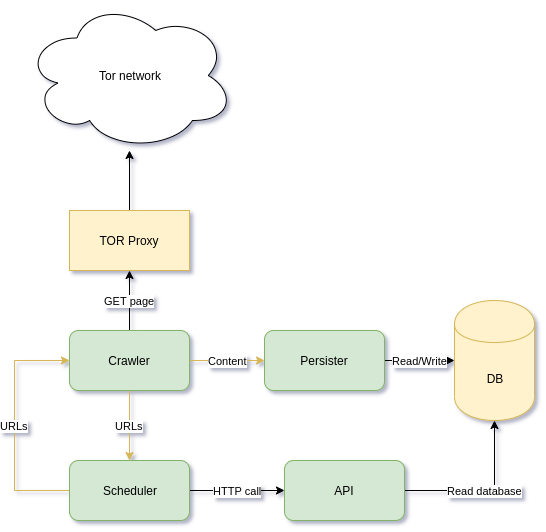
Before talking about the responsibility of each process it is important to understand how they talk to each others.
The inter process communication (IPC) is mainly done using a messaging protocol known as NATS (yellow line in the diagram) based on the producers / consumers pattern. Each message in NATS has a subject (like an email) that allow other process to identify it and therefore to read only messages they want to read. NATS allowing scaling: for example they can be 10 crawler processes reading URL from the messaging server. Each of these process will receive an unique URL to crawl. This allow process concurrency (many instances can run at the same time without any bugs) and therefore increase performances.
Trandoshan is divided in 4 principal processes:
- Crawler: The process responsible of crawling pages: it read URLs to crawl from NATS (message identified by subject “todoUrls”), crawl the page, and extract all URLs present in the page. These extracted URLs are sent to NATS with subject “crawledUrls”, and the page body (the whole content) is sent to NATS with subject “content”.
- Scheduler: The process responsible of URL approval: this process read the “crawledUrls” messages, check if the URL is to be crawled (if the URL has not been already crawled) and If so, send the URL to NATS with subject “todoUrls”
- Persister: The process responsible of content archiving: it read page content (message identified by subject “content”) and store them into a NoSQL database (MongoDB).
- API: The process used by other process to gather informations. For example it is used by the Scheduler to determinate if a page has been already crawled. Instead of directly calling the database to check if an URL exist (which would add extra coupling to the database technology) the scheduler use to API: this allow sort of abstraction between database / processes.
The different processes are written using Go: because it offer a lot of performance (since it’s compiled as native binary) and has a lot of library support. Go is perfectly designed to build high performance distributed systems.
The source code of Trandoshan is available on github here: https://github.com/trandoshan-io.
How to run Trandoshan?⌗
As said before Trandoshan is designed to run on distributed systems and is available as docker image which make it a great candidate for the cloud. In fact there is a repository which hold all configurations files needed to deploy a production instance of Trandoshan on a Kubernetes cluster. The files are available here and the containers images are on docker hub.
If you have a kubectl configured correctly, you can deploy Trandoshan in a simple command:
./bootstrap.sh
Otherwise you can run Trandoshan locally using docker and docker-compose. In the trandoshan-parent repository there is a compose file and a shell script that allow the application to run using the following command:
./deploy.sh
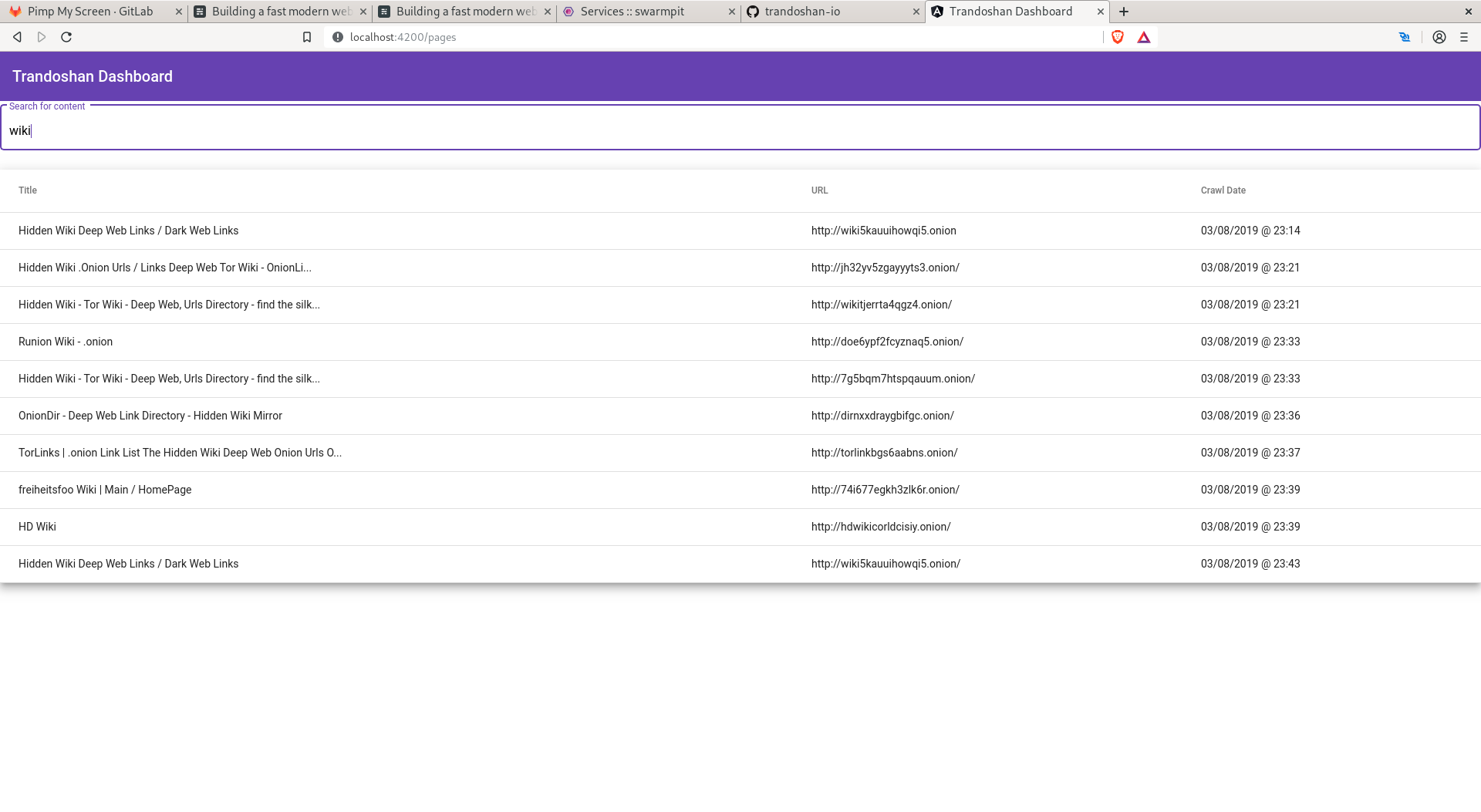
How to use Trandosan?⌗
At the moment there is a little Angular application to search for indexed content. The page use the API process to perform search on the database.
Conclusion⌗
That’s all for the moment. Trandoshan is production ready but there’s a lot of optimization to be done and features to be merged. Since it’s an open source project everyone can contribute to it by doing a pull request on the corresponding project.
Happy hacking!
N-B: trandoshan has been rewritten, and now lies in a single repository available here